Blog Digitalgesellschaft Verwaltungsbetrieb Textarchiv Textarchiv Walter Kirk (✝) Impressum
Audiobook erstellen (.m4b) - I: Grundsäztliches
📑 Inhaltsverzeichnis
→ Vorbemerkung
→ Voraussetzungen
→ System
→ Audio
→ Metadaten
→ Speicherort
→ Vorgehensweise
→ Schritt 1: Ordnername vergeben
→ Schritt 2: Transcodieren nach .m4b
→ Schritt 3: Liste der Dateien erstellen
→ Schritt 4: Gesamtdateien erstellen
→ Schritt 5: Metadaten der Kapitel ermitteln und erfassen
→ Laufzeit ermitteln - Teil 1
→ Metadaten bearbeiten
→ Schritt 6: Audiobook mit Metadaten versehen
→ Schritt 7: Hörbuch mit Cover versehen
→ Schritt 8: Umbenennen
→ Schritt 9: Sonstiges
→ Ergebnis
→ Dauer nachträglich ermitteln
→ Audacity
→ VLC Media Player
→ Dateien umbenennen
→ Schritt 1: Titelangaben extrahieren
→ Schritt 2: Nummerierung
→ Schritt 3: Dateinamen ändern
→ Schritt 4: Erweiterung hinzufügen
→ Umwandlung in Videoformate
→ Bash-Skript
→ Erweiterung hinzufügen (.ext)
→ Quelle: John Otieno
→ https://linuxhint.com/change-file-extension-multiple-files-bash/
→ Hier * eingeben, wenn keine Erweiterung vorhanden ist.
→ Umwandlung zu .m4b
→ 1. Schritt
→ a Transcodieren nach m4b
→ b) Fileliste erstellen von .mp3 und .m4b
→ https://bbs.archlinux.org/viewtopic.php?id=288553
→ 2. Schritt
→ Gesamtdateien erstellen
→ 3. Schritt
→ Laufzeit der einzelnen Kapitel ermitteln
→ sudo apt install mediainfo
→ 4. Schritt
→ meta.xt um Kapitel manuell ergänzen, deshalb Ausführung pausieren
→ Fortsetzen mit beliebiger Tast
→ 5. Schritt
→ m4b mit Kapitelangaben ergänzen
→ Sonstige Schritte
→ a) Mp3 ergänzen mit Metadaten und Cover
→ b) m4b ergänzen mit Cover
→ c) Umbenennen
→ d) Ordner bereinigen
→ Umwandlung .m4b zu .m4v, .mp4 und .webm
→ Transcoding .m4b to .m4v or .mp4 or .webm
→ Kapitelmarken bleiben erhalten
→ .m4v
→ .mp4
→ .webm
→ Umwandlung .mp3 zu .wav
→ Bezugsquellen für Audiobook
→ Download
→ RSS-Feed
→ Programm zum Herunterladen
→ Laufzeit ermitteln - Teil 2
→ Nachträgliche Änderung der Kapitelnamen
→ Automatisierte Erstellung
→ Hörbuchverwaltung
→ Speicherort der Audiobook
→ Einstellungen
→ Metadaten für Cozy
→ Ansicht
→ Entfernen von Audiobook
→ Pro und Kontra
→ Pro
→ Kontra
→ Literatur
→ Zusammenfassung
→ Mindmap
Vorbemerkung
Der Vorteil von Hörbüchern als .m4b liegt an der Möglichkeit, Kapitel zu markieren. Heute lassen sich .m4b nicht mehr nur auf von Apple Inc. vertriebenen Geräten nutzen, sondern das Format steht auf allen gängigen Betriebssystemen zur Verfügung.
Allerdings ist die Einbindung von Markierungen der Kapitel nicht wie gewohnt mit einem Klick zu vollziehen. Auch sind die Hinweise im Internet unter Umständen überholt, weil sich die Betriebssysteme und die Programme weiter entwickelt haben. Oder für Linux sind entsprechende Programme nicht verfügbar.
Voraussetzungen
System
Als Betriebssystem ist Ubuntu 24.04 für diese Beschreibung genutzt worden. Notwendige Programme sind: AtomicParsley, ffmpeg, mediainfo, Libre Office (CALC). Die Ausführung erfolgt in einem Bash-Skript auf der Kommandozeilen-Ebene (Terminal).
Audio
Als Grundlage für die Erstellung werden im Beispiel .mp3 voraus gesetzt.
Metadaten
Wenn der Herausgeber und Vertreiber die .mp3 entsprechend gekennzeichnet hat, sollten die Metadaten bereits enthalten sein. Darüber hinaus sind vielleicht auch die Kapitel als Dateinamen vorhanden. Sollten entsprechende Angaben nicht vorhanden sein, sind die .mp3 mit Metadaten zu versehen und ist ein Inhaltsverzeichnis beim Herausgeber zu ermitteln. Inlays von Audio-CD können Kapitel-/Titelnamen enthalten.
Auch die Suche beim Deutschen Rundfunkarchiv - Bereich ARD-Hörspieldatenbank - kann hilfreich sein, wenn es sich um Aufnahmen der öffentlich-rechtlichen Rundfunkanstalten in Deutschland, einschließlich solcher der ehemaligen DDR, handelt.
Die Metadaten lassen sich auch manuell in der meta.txt erfassen (s. Schritt 5).
Tipp
Eine Suchmaschine mit KI-Suchfunktion erleichtert die Ermittlung der Episodentitel, wenn man eingibt: Herausgeber, Bezeichnung, Art, Anzahl Episoden, Titel
Beispiel: Krien Mein drittes Leben Hörspiel 15 Episoden Titel
Speicherort
Alle Audio-Dateien (.mp3) und das Cover sind im selben Verzeichnis gespeichert.
Im Beispiel ist das Buchcover als cover.jpg im Bash-Script vorgegeben. Für das Einfügen in .m4b ist das Format .jpg oder .png möglich. Änderungen des Formates oder des Bildnamens sind anpassbar.
Das Verzeichnis enthält folgende Ordner:
│nossow-nikolai-nimmerklug-im-knirpsenland ├── gesamt ├── m4b ├── mp3 └── sonstiges
Vorgehensweise
Schritt 1: Ordnername vergeben
Die Ordernamen werden als Bezeichnung der Hörbücher übernommen. Das Format ist:
Name-Vorname-Titel.m4b
Beispiel: nossow-nikolai-nimmerklug-im-knirpsenland.m4b
Natürlich ist das Format den eigenen Vorstellungen entsprechend anzupassen. Die Festlegung sollte jedoch einheitlich erfolgen und die Namensvergabe muss vor dem Erstellungsprozess vollzogen sein.
Schritt 2: Transcodieren nach .m4b
Jede einzelne .mp3 ist zu Konvertieren.
Schritt 3: Liste der Dateien erstellen
Die .txt muss die Daten im Format file 'Dateiname' enthalten. Im Beispiel werden erstellt listmp3.txt, listm4b.txt mit dem Inhalt:
xxxxxxxxxxfile 'Nimmerklug im Knirpsenland 01.mp3'bis ~11.mp3
Entsprechend ist der Inhalt für .m4b.
Die Umwandlung erfolgt mit ffmpeg:
xxxxxxxxxxfor f in *.mp3; do ffmpeg -i "$f" -vn -ar 48000 -b:a 320k -c:a aac "${f%.mp3}.m4b" ; done
Die o.a. Angaben sind voreingestellte Werte. Die Qualität der Ausgabe lässt sich auf die eigenen Bedürfnisse anpassen. Die Option -vn bedeutet, dass keine Videobearbeitung erfolgt.
Schritt 4: Gesamtdateien erstellen
Das Hörbuch als Gesamtdatei im Format .mp3 und .m4b wird erstellt mit:
xxxxxxxxxxffmpeg -f concat -safe 0 -i listmp3.txt -c copy output.mp3 &&ffmpeg -f concat -safe 0 -i listm4b.txt -c copy output.m4b
Anhand der Dateilisten erfolgt die Kombination zu einer Gesamtdatei als output.mp3 und output.m4b.
Schritt 5: Metadaten der Kapitel ermitteln und erfassen
Alle Angaben der Kapitel sind in eine separate meta.txt einzugeben. Dazu sind auch die Laufzeiten der einzelnen Audiodateien zu ermitteln (.m4b).
Laufzeit ermitteln - Teil 1
Die Laufzeit der .m4b wird ermittelt mit
xxxxxxxxxxfor f in *.m4b; do mediainfo --Output='General;%Duration%' "$f"; done >duration.csv
und wird als duration.csv ausgegeben.
Die .csv wird mit CALC oder EXCEL aufgerufen, sodass die genauen Angaben rechnerisch ermittelt werden können. Im Beispiel enthält die .csv folgende Daten in Spalte A:
xxxxxxxxxx417620452441 870061 (=A1+A2)388494 1258555 (=B2+A3)386090 1644645 usw.395886 2040531467618 2508149511086 3019235435357 3454592484676 3939268312477 4251745331756 4583501
In Spalte B sind durch Eingabe entsprechender Formeln die Endzeiten der Audiodateien zu ermitteln. Diese Angaben werden in die meta.txt übertragen.
Metadaten bearbeiten
Der Aufbau der Kapitelangaben ist vorgegeben. Im Beispiel enthält die Datei neben den allgemeinen Angaben auch die Angaben zu insgesamt 11 Kapitel:
x;FFMETADATA1major_brand=M4Aminor_version=512compatible_brands=M4A isomiso2title=Nimmerklug im Knirpsenlandartist=Nilolai Nossowalbum_artist=Variousalbum=Nimmerklug im Knirpsenlanddate=2015copyright=DAVcomment=zusammen gestellt 2024-07-02genre=Audiobookencoder=Lavf60.3.100[CHAPTER]TIMEBASE=1/1000START=0END=417619title=Chapter 1[CHAPTER]TIMEBASE=1/1000START=417620END=870059title=Chapter 2[CHAPTER]TIMEBASE=1/1000START=870060END=1258552title=Chapter 3usw. bis Kapitel 11
Die Endzeit ist 1ms weniger als die neue Startzeit. Der Titel Chapter 1, usw. lässt sich entsprechend den eigenen Verhältnissen anpassen. Alle übrigen Daten sind vorgegeben.
Schritt 6: Audiobook mit Metadaten versehen
Die output.m4b wird um die Angaben zu den Kapiteln ergänzt mit:
xxxxxxxxxxfor f in output.m4b; do ffmpeg -i "$f" -f ffmetadata -i meta.txt -map_metadata 1 -map 0 -codec copy out-"${f#./}" && mv out-"${f#./}" "$f"; done
Die output.mp3 wird um die Metadaten und das Cover ergänzt:
xxxxxxxxxxfor f in output.mp3; do ffmpeg -i "$f" -f ffmetadata -i meta.txt -map_metadata 1 -codec copy out-"${f#./}" && mv out-"${f#./}" "$f"; donefor f in output.mp3; do ffmpeg -i "$f" -i cover.jpg -map 0 -codec copy out-"${f#./}" && mv out-"${f#./}" "$f"; done
Das Programm FFmpeg kann nur in eine neue temporäre Datei out-output.mp3 bzw. .m4b schreiben und mit mv wird der Originalname output.mp3 bzw output.m4b deshalb wieder hergestellt.
Im Beispiel führt die Ergänzung in dieser geteilten Weise zum gewünschten Ergebnis und verursacht keine Fehlermeldungen.
Die Angaben zu den Kapiteln in der meta.txt werden nicht in die .mp3 übernommen.
Schritt 7: Hörbuch mit Cover versehen
Das Buchcover wird mit AtomicParsley in die .m4b eingebettet:
xxxxxxxxxxfor f in ./*.m4b; do AtomicParsley "$f" --artwork cover.jpg --overWrite ; done
Schritt 8: Umbenennen
Die erstellten output.* werden umbenannt und in das Verzeichnis gesamt verschoben:
xxxxxxxxxxfor f in output.mp3 ; do mv "$f" "$(basename "$(pwd)")".mp3 ; done && mv "$(basename "$(pwd)")".mp3 ./gesamt/for f in output.m4b ; do mv "$f" "$(basename "$(pwd)")".m4b ; done && mv "$(basename "$(pwd)")".m4b ./gesamt/
Schritt 9: Sonstiges
Das Verzeichnis wird bereinigt, in dem die Dateien in entsprechende Verzeichnisse verschoben werden (keine Löschung).
Ergebnis
War die Ausführung erfolgreich, ist der Verzeichnisinhalt im Beispiel wie folgt aufgebaut:
xxxxxxxxxx│nossow-nikolai-nimmerklug-im-knirpsenland├── gesamt│ ├── nossow-nikolai-nimmerklug-im-knirpsenland.m4b│ └── nossow-nikolai-nimmerklug-im-knirpsenland.mp3├── m4b│ ├── Nimmerklug im Knirpsenland 01.m4b│ ├── usw bis *11.m4b│ └── duration.csv├── mp3│ ├── Nimmerklug im Knirpsenland 01.mp3│ └── usw. bis *11.mp3├── sonstiges│ ├── cover.jpg│ ├── listm4b.txt└── └── listmp3.txt
Im VLC Media Player können die einzelnen Kapitel ausgewählt werden:
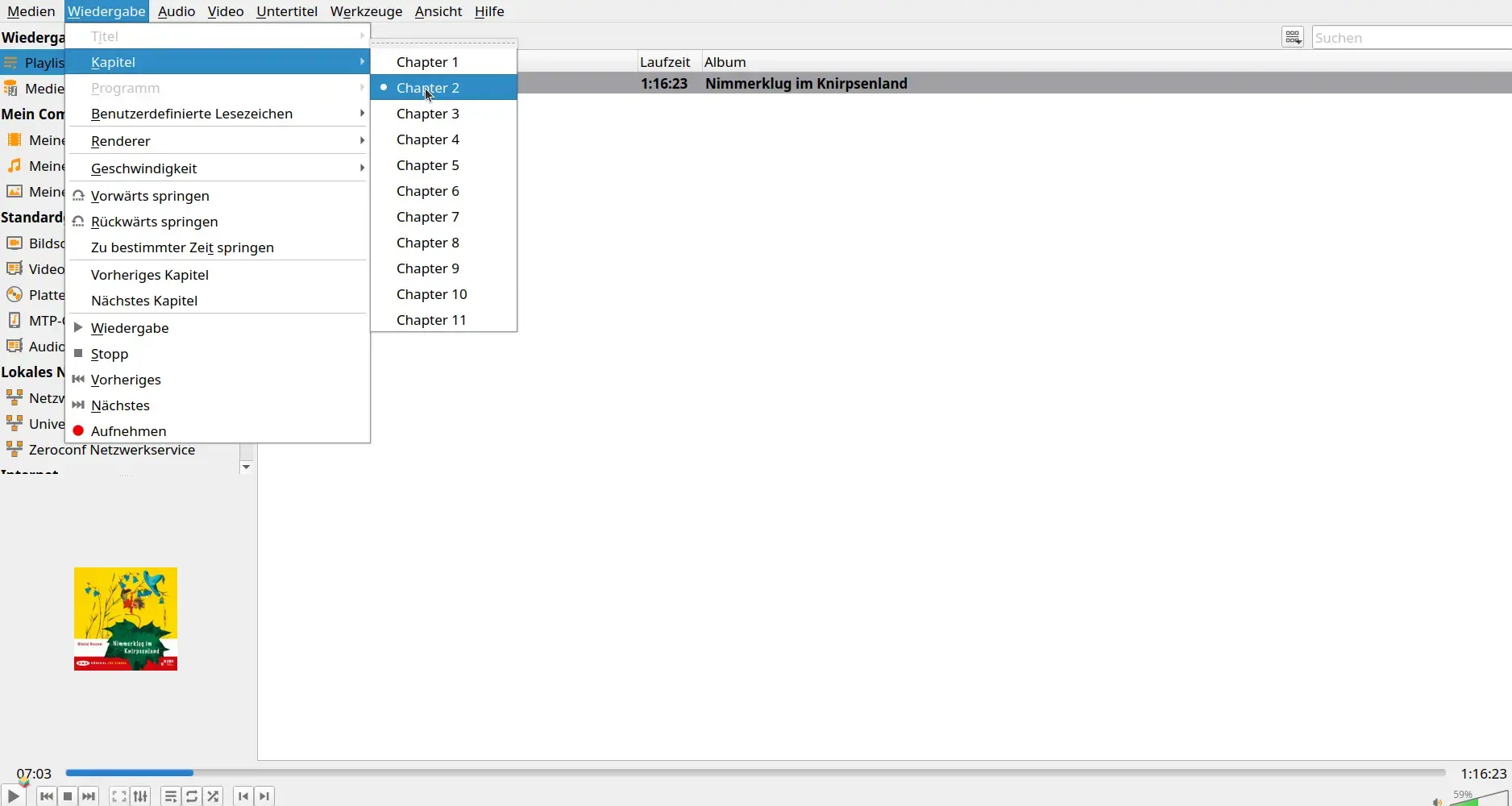
In der unteren Bildschirmleiste können die Kapitel mit den Schaltern vor oder zurück angesteuert werden.
Dauer nachträglich ermitteln
Audacity
Liegen die Audiodateien als .wav vor, lässt sich die Dauer der Kapitel, Abschnitte, etc. mit Hilfe von Audacity genau ermitteln und sogar in eine .txt speichern.
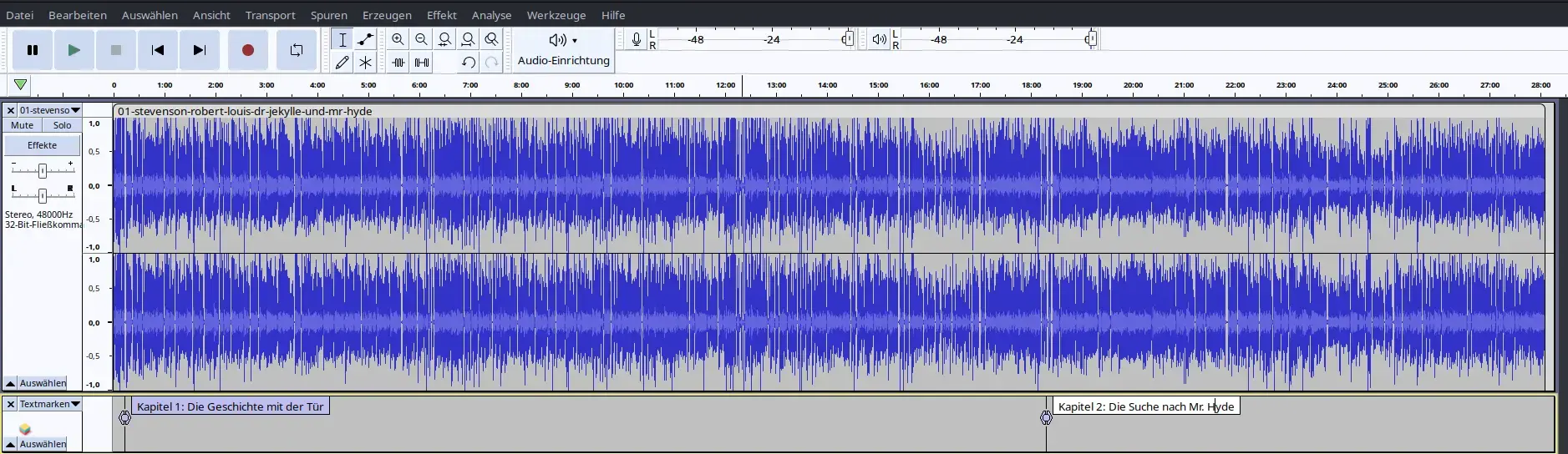
Weitere Info unter
http
VLC Media Player
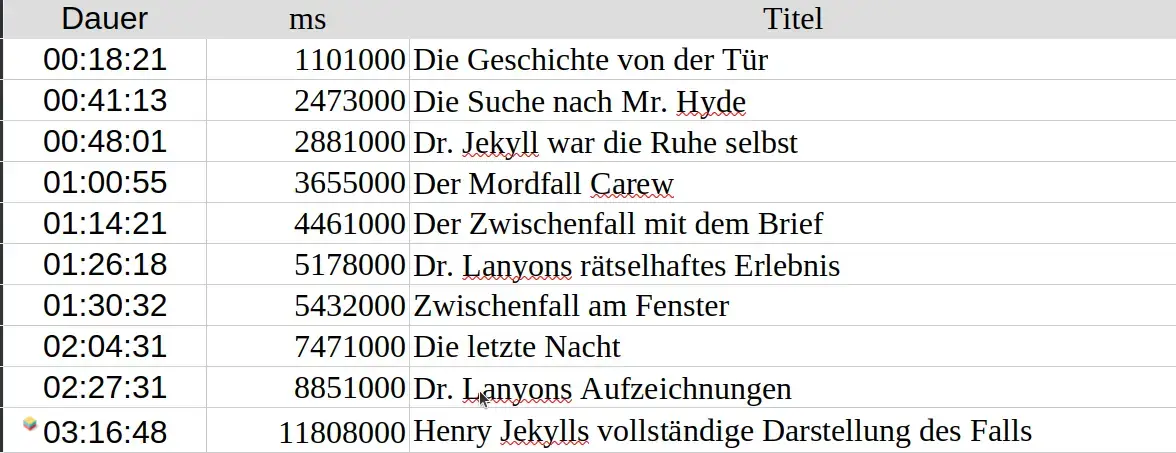
Der VLC Media Player zeigt die Abspielzeit an. Wenn beim Abhören die Angabe der Kapitel, etc. efolgt, lassen sich die Werte der Abspielzeit in eine Tabelle übertragen und in Millisekunden (ms) umrechnen. In A1 werden Zeiten in Form von HH:MM:SS erfasst, in B1 werden die ms mit Hilfe der Formel
xxxxxxxxxx=A1*(24*60*60*1000)
ermittelt. Die Werte für ms lassen sich wie oben dargestellt in die meta.txt übernehmen.
Dateien umbenennen
In einigen Fällen werden die Audiodateien ohne genaue Angabe von Kapitel, etc., in den Dateinamen zur Verfügung gestellt, z.B. Track 1.wav, usw.
Schritt 1: Titelangaben extrahieren
Die Titelangabe title kann aus der meta.txt ausgelesen und in einer separaten track.txt gespeichert werden:
xxxxxxxxxxtest@geraet:~$ grep ^title meta.txt >track.txt
In den Titelangaben fehlt die Nummerierung und die Angabe von .ext.
Schritt 2: Nummerierung
Die Nummerierung wird im Beispiel in der Form 00-Titel in die track.txt eingetragen.
1. Alternative
xxxxxxxxxxtest@geraet:~$ while read num; do printf '%0.2d\n' "$num"; done <track.txt
2. Alternative
xxxxxxxxxxtest@geraet:~$ awk '{printf("%0.2d-%s\n", NR,$0)}' track.txt > output.txt && mv output.txt track.txt
Eine mehrstellige Ziffer wird mit *%0.*d\n' eingetragen, wobei * die Anzahl der Stellen angibt: 3 für 000, 4 für 0000, usw. .
Schritt 3: Dateinamen ändern
Sodann können die vorhandenen Audiodateien umbenannt werden mit:
xxxxxxxxxxtest@geraet:~$ for old in *.*; do read new; mv -v "${old}" "${new}"; done < track.txt
Schritt 4: Erweiterung hinzufügen
Die .ext kann nachgetragen werden mt:
1. Alternative
xxxxxxxxxxtest@geraet:~$ for num in ./*; do mv ${num} ${num%.*.*}.ext; done
2. Alternative
xxxxxxxxxxtest@geraet:~$ for f in * ; do mv "$f" "$f.ext" done
.ext ist mit den benötigten Daten zu ersetzen, z.B. .wav, .m4b, .mp3 etc.
Vereinfacht geht das Hinzufügen von .ext mit Hilfe eines Bash-Scripts (s. Abschnitt Bash-Script)
Umwandlung in Videoformate
.m4b lässt sich in verschiedene Videoformate umwandeln, z.B. .m4k, .mp4 und .webm. Kapitelmarken bleiben erhalten. Der Prozess lässt sich mit einem Bash-Script für alle Ausgabeformate vereinfacht ausführen (s. folgenden Abschnitt).
Bash-Skript
Erweiterung hinzufügen (.ext)
Das unten aufgeführte Script in eine extension-hinzufügen.sh speichern, die Ausführung als Recht setzen und im Terminal ausführen:
xxxxxxxxxx#!/bin/bash# Quelle: John Otieno# https://linuxhint.com/change-file-extension-multiple-files-bash/echo "Geben Sie das Zielverzeichnis ein"read target_dircd $target_direcho "Geben Sie die zu suchende Dateierweiterung ohne Punkt ein"read old_ext# Hier * eingeben, wenn keine Erweiterung vorhanden ist.echo "Geben Sie die neue Dateierweiterung zum Umbenennen ohne Punkt ein"read new_extecho "$target_dir, $old_ext, $new_ext"for file in *.$old_extdomv -v "$file" "${file%.$old_ext}.$new_ext"done;
Umwandlung zu .m4b
Das unten aufgeführte Script in eine audiobook.sh speichern, die Ausführung als Recht setzen und im Terminal ausführen:
xxxxxxxxxx#!/bin/sh# 1. Schritt# a Transcodieren nach m4bfor f in *.mp3; do ffmpeg -i "$f" -vn -ar 48000 -b:a 320k -c:a aac "${f%.mp3}.m4b" ; done# b) Fileliste erstellen von .mp3 und .m4b# https://bbs.archlinux.org/viewtopic.php?id=288553printf "file '%s'\n" *.mp3 > listmp3.txtprintf "file '%s'\n" *.m4b > listm4b.txt# 2. Schritt# Gesamtdateien erstellenffmpeg -f concat -safe 0 -i listmp3.txt -c copy output.mp3 &&ffmpeg -f concat -safe 0 -i listm4b.txt -c copy output.m4b# 3. Schritt# Laufzeit der einzelnen Kapitel ermitteln# sudo apt install mediainfofor f in *.m4b; do mediainfo --Output='General;%Duration%' "$f"; done >duration.csv# 4. Schritt# meta.xt um Kapitel manuell ergänzen, deshalb Ausführung pausieren# Fortsetzen mit beliebiger Tastecho "Fortsetzen mit beliebiger Taste ... "stty -icanon -echo min 1 time 0dd bs=1 count=1 >/dev/null 2>&1stty stty -gecho# 5. Schritt# m4b mit Kapitelangaben ergänzenfor f in output.m4b; do ffmpeg -i "$f" -f ffmetadata -i meta.txt -map_metadata 1 -map 0 -codec copy out-"${f#./}" && mv out-"${f#./}" "$f"; done# Sonstige Schritte# a) Mp3 ergänzen mit Metadaten und Coverfor f in output.mp3; do ffmpeg -i "$f" -f ffmetadata -i meta.txt -map_metadata 1 -map 0 -codec copy out-"${f#./}" && mv out-"${f#./}" "$f"; donefor f in output.mp3; do ffmpeg -i "$f" -i cover.jpg -map_metadata 0 -map 0 -map 1 -codec copy out-"${f#./}" && mv out-"${f#./}" "$f"; done# b) m4b ergänzen mit Coverfor f in ./*.m4b; do AtomicParsley "$f" --artwork cover.jpg --overWrite ; done# c) Umbenennenfor f in output.mp3 ; do mv "$f" "$(basename "$(pwd)")".mp3 ; done && mv "$(basename "$(pwd)")".mp3 ./gesamt/for f in output.m4b ; do mv "$f" "$(basename "$(pwd)")".m4b ; done && mv "$(basename "$(pwd)")".m4b ./gesamt/# d) Ordner bereinigenmv *.jpg *.txt ./sonstiges/ && mv *.mp3 ./mp3/ && mv *.m4b ./m4b/ && mv *.csv ./m4b/
Umwandlung .m4b zu .m4v, .mp4 und .webm
Das unten aufgeführte Script in eine video-transcode.sh speichern, die Ausführung als Recht setzen und im Terminal ausführen:
xxxxxxxxxx#!/bin/bash# Transcoding .m4b to .m4v or .mp4 or .webm# Kapitelmarken bleiben erhalten# .m4vfor FILE in *.m4b ; do ffmpeg -i "$FILE" -vn -ar 48000 -b:a 320k -c:a aac "${FILE%.m4b}.m4v"; done# .mp4for FILE in *.m4b ; do ffmpeg -i "$FILE" -vn -ar 48000 -b:a 320k -c:a aac "${FILE%.m4b}.mp4"; done# .webmfor FILE in *.m4b ; do ffmpeg -i "$FILE" -vn -b:v 1M -c:a libvorbis "${FILE%.m4b}.webm"; done
Da Videodaten nicht vorhanden sind, wird mit -vn das Transcodieren der Videospur unterbunden (= Video no).
Umwandlung .mp3 zu .wav
Ältere Aufnahmen im Format .mp3 oder von LibriVox bereit gestellte .mp3, .m4b sind teilweise in einer geringwertigen Qualität (z.B. Mono). Insbesondere bei Hörspielen mit Musikanteilen führt dies oft zu Beeinträchtigungen in der Wahrnehmung (Subjektivität).
| Distributor | Qualität | Medium |
| ARD / ZDF | 44000 Hz, 128/256 kb/s, mono/stereo | Stream, Podcast |
| Verlage | 44000 Hz, 128/256 kb/s, mono/stereo | MC, .mp3, CD, DVD |
| LibriVox | 44000 Hz, 64/128 kb/s, mono | .mp3 |
| LibriVox | 32000 Hz, 65 kb/s, mono | .m4b |
Um die Qualität etwas zu verbessern, lassen sich .mp3 in das höherwertige .wav-Format transcodieren, z.B. mit 2 Kanälen (Stereo). In einem Terminal wird dazu FFmpeg ausgeführt:
xxxxxxxxxxfor file in *.mp3; do fname=$(basename "$file" .mp3); ffmpeg -i "$file" -vn -ac 2 -c:a pcm_s32le -ar 48000 -rf64 auto "$fname".wav; done
Neben den für .wav typischen Werten wird zusätzlich angegeben Audio Channel 2 (Stereo): -ac 2.
Diese Umwandlung ist nicht die beste Form, weil eine minderwertige Qualität eigentlich dadurch nicht verbessert wird, kann aber in Einzelfällen die subjektive Wahrnehmung der bereit gestellten Audiodateien deutlich verbessern. Deshalb ist ein Test ratsam, um die eigenen Präferenzen festzustellen.
Bezugsquellen für Audiobook
Download
Bei folgenden Quellen erhält man kostenfreie Audiobook:
| Distributor | Kanäle | Frequenz | Sample | Format | Bitrate |
| ARD-Audiothek | 1 bzw. 2 | 44000 Hz | 16 bit | mp3 | 128 kb/s |
| LibriVox | 1 | 44000 Hz | 16 bit | .mp3 | 128 kb/s |
| LibriVox | 1 | 44000 Hz | 16 bit | .m4b | 65 kb/s |
| ORF Ö1 Hörspiel | 2 | 44000 Hz | 16 bit | .mp3 | 192 kb/s |
| SRF Hörspiel | 2 | 48000 Hz | 16 bit | .mp3 | 192 kb/s |
URL.:
ARD Audiothek: http
LibriVox: http
ORF Ö1 Hörspiel: http
SRF Hörspiel: http
RSS-Feed
Die ARD-Audiothek enthält keine RSS-Feed zum einfachen Herunterladen. Das Auffinden solcher Listen in den Angeboten der Regionalsender der ARD ist zeitaufwendig. Aber es lohnt sich.
Für einige Angebote des öffentlich-rechtlichen Rundfunks in Deutschland (ÖRR) sind die RSS-Feeds in der folgenden .opml zusammen gestellt (Stand: 2024-10-14, ohne Gewähr): hoerbuch-abo.opml. Download mit Rechts-Klick und Ziel speichern unter.
Diese Liste kann in jeden Podcatcher importiert werden, z.B. gPodder.
Programm zum Herunterladen
Der Entwickler des Programms MediathekView stellt mit der Software ATPlayer ein Tool zur Verfügung, mit dem sich die Audiobooks in der ARD-Audiothek anhören und herunter laden lassen (Linux, Windows).
Laufzeit ermitteln - Teil 2
Zum Abspielen der Audio-/Videodateien ist es sinnvoll, eine Übersicht über die Laufzeit für jeden einzelnen Titel (z.B. sortiert nach der Abspieldauer) sowie die Gesamtlaufzeit alle Titel in einem Verzeichnis zu erstellen.
xxxxxxxxxxtest@geraet:~$ for f in *; do ffmpeg -i "$f" 2>&1 | grep Duration | cut -d " " -f 4 | sed s/,// | tr -d "\n" && echo " $f"; done > 00-duration-list.csv
Die Angaben werden in die Datei 00-duration-list.csv geschrieben und können mit einer Tabellenkalkulation angesehen bzw. bearbeitet werden.
Quelle: https://askubuntu.com/questions/224237/how-to-check-how-long-a-video-mp4-is-using-the-shell
Die Gesamtspielzeit wird mit Hilfe eines Bash-Scripts ermittelt:
xxxxxxxxxx#!/bin/bash#Quelle:#https://www.reddit.com/r/linuxquestions/comments/3b93uv/i_have_multiple_audio_fi#les_in_a_folder_and_i/?rdt=62144tot=0while read -r idotmp=0tmp=`ffprobe "$i" -show_format 2>/dev/null | grep "^duration" | cut -d '=' -f 2 | cut -d '.' -f 1`if [ -n "$tmp" ]; thenlet tot+=$tmpfidone < <(find . -type f -iname "*[.mp3,.m4b,.mp4,.wav]")echo "Total duration: $(($tot/60)) minutes"
Als Ergebnis wird anezeigt:
xxxxxxxxxxtest@geraet:~$ Total duration: #### minutes
Nachträgliche Änderung der Kapitelnamen
Die Kapitelnamen lassen sich mit FFmpeg nachträglich ändern und in die .m4b einfügen:
xxxxxxxxxxtest@geraet:~$ ffmpeg -i input.m4b -i meta.txt -map_metadata 1 -map_chapters 1 -vn -codec copy output.m4b
Automatisierte Erstellung
Wer eine vollständig automatisierte Erstellung von .m4b bevorzugt, sollte sich das Bash-Script chapters.sh von Jeff Channel ansehen, das auf .m4b umgestellt und auf die eigenen Verhältnisse angepasst werden kann. Download unter: FFMETADATA Chapter generator.
Hörbuchverwaltung
Das Programm Cozy ist ein einfach zu bedienender Audiobook Player für Linux, der auch .m4b abspielen kann. Daüber hinaus ist Cozy auch eine einfache Hörbuchverwaltung.
Die Installation unter Ubuntu setzt die Einrichtung von Flatpak voraus und erfolgt mit:
xxxxxxxxxxtest@geraet: $ flatpak install cozy
Das Programm ist von der Bedienung her selbst erklärend.
Speicherort der Audiobook
Alle Audiobook sind in einem Verzeichnis abgespeichert (Kopie/Arbeitsverzeichnis). Dann kann diese Kopie (.mp3, .m4b) in Cozy selbst von dem Datenträger gelöscht werden, ohne das es zu einem Verlust der Datei(en) kommt.
Einstellungen
Damit in der Gesamtübersicht die Metadaten (=Titeldaten) korrekt angezeigt werden, ist die Einstellung Tausche Autor und Leser unter Tags hilfreich.
Der Speicherort (Kopie/Arbeitsverzeichnis) wird als Quelle unter Speicher eingestellt.
Metadaten für Cozy
Cozy liest die Meta-Daten aus für album und artist, das heißt, das die beiden Daten in der meta.txt zwingend ausgefüllt werden müssen.
Ansicht
In Cozy werden die Kapitelmarken angezeigt und können vereinfacht ausgewählt werden.
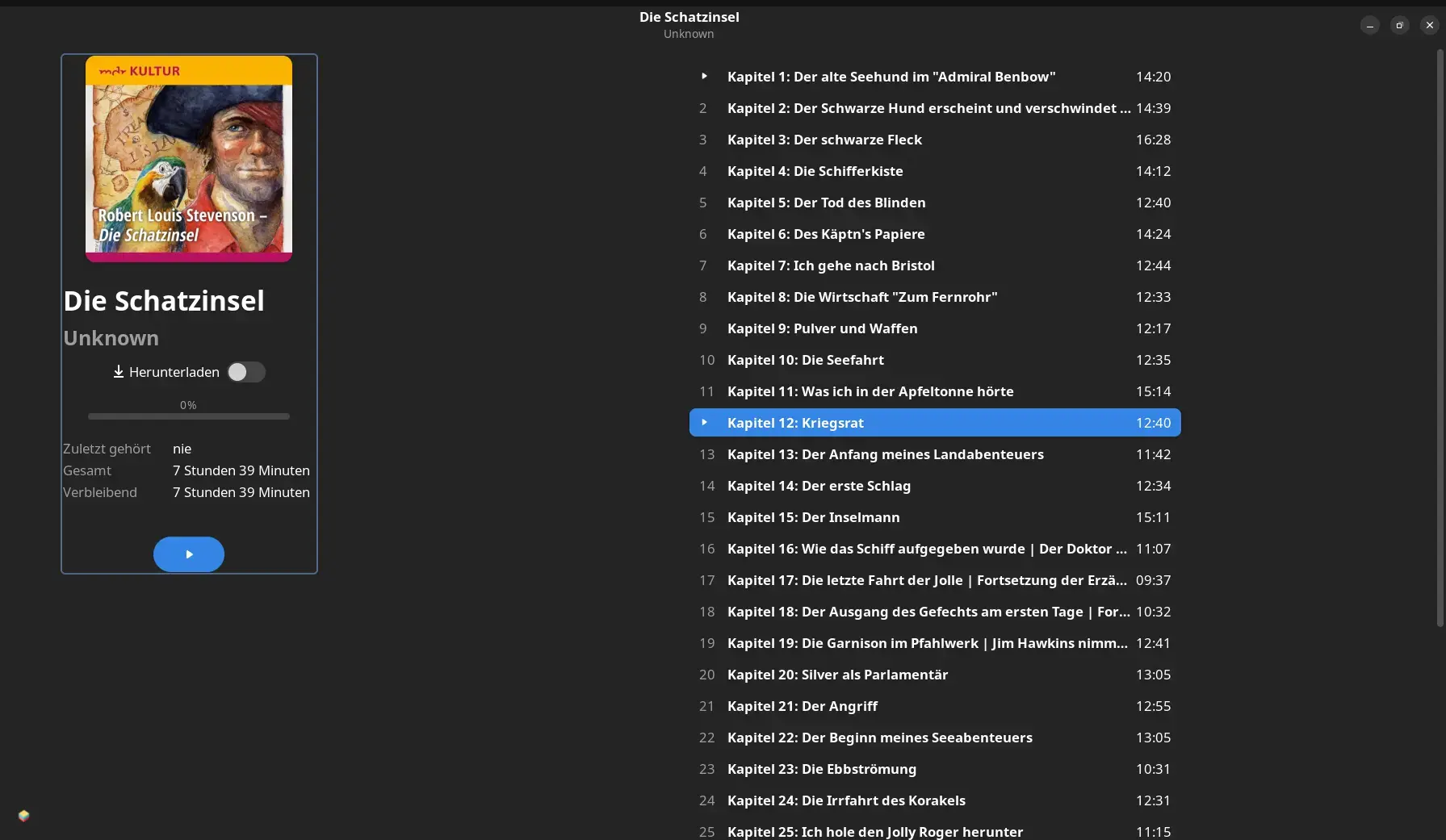
Entfernen von Audiobook
Die Möglichkeit, mit Cozy Hörbücher aus der Bibliothek zu entfernen, sollte nur dann genutzt werden, wenn auch das Löschen auf dem Datenträger gewünscht wird.
Pro und Kontra
Pro
1. .m4b lassen sich mit Kapitelmarker versehen und insoweit frei gestalten
2. Für die Erstellung lassen sich kostenfreie Programme nutzen (Open Source)
3. Die aufgezeigte Vorgehensweise lässt sich auch für andere Audio-\Videodateien nutzen (.mp3, .mp4)
3. Aufwand für die Einarbeitung in wenige Programme ist überschaubar
4. Keine Nutzung von Online-Diensten: Alle Vorgänge erfolgen unter eigener Kontrolle auf dem eigenen PC.
Kontra
1. Bei .m4b mit umfangreichen Kapiteln ist der Zeitaufwand für die manuelle Erfassung der Kapiteltitel und der Dauer (Duration) durchaus aufwendig
2. Die aufgezeigte Vorgehensweise ist nicht geeignet für die Erstellung massenhafter .m4b
3. Grundkenntnisse in der Nutzung von Linux und technisches Verständnis sind vorteilhaft, aber keine notwendige Voraussetzung.
Literatur
Hinweise und Erläuterungen:
http
http
http
http
http
http
http
http
Zusammenfassung
Die Erstellung von Hörbüchern im Format .m4b ist nicht die einzige Möglichkeit, die Vorgehensweise zu nutzen. Hilfreich kann es sein, auch die eigenen Podcast als .mp4 mit Kapitel zu markieren. Dafür lässt sich das Skript entsprechend anpassen.
Wer also die manuelle Bearbeitung der Metadaten nicht scheut, kann sich mit der Ausführung des Bash-Skriptes viel Arbeit und Zeit sparen.
Darüber hinaus werden zielgerichtet brauchbare Ergebnisse erstellt.
Mindmap

Wolfgang Kirk
Veröffentlicht: 2024-07-04 aktualisiert: 2025-06-03, 13:00 Uhr